반응형

1. 생명과학을 위한 딥러닝
2. install
3. tutorial
1. 생명과학을 위한 딥러닝
- from ChatGPT
『생명과학을 위한 딥러닝』은 딥러닝과 생명과학 분야의 교차점을 탐구하는 책이다. Bharath Ramsundar, Peter Eastman, Patrick Walters 및 Vijay Pande가 작성했으며 2019년에 출판되었습니다.
이 책은 딥 러닝에 대한 포괄적인 소개와 약물 발견, 유전체학, 단백질 구조 예측과 같은 생명 과학의 다양한 문제에 대한 적용을 제공합니다. 기계 학습 및 프로그래밍에 대한 기본적인 이해가 있는 독자를 위해 설계되었으며 실습 예제 및 코드 스니펫을 통해 딥 러닝에 대한 실용적인 접근 방식을 제공합니다.
책은 세 부분으로 나뉩니다.
첫 번째 부분에서는 딥 러닝과 생명 과학에서의 응용 프로그램에 대한 소개와 책에서 사용된 도구 및 프레임워크에 대한 개요를 제공합니다.
두 번째 부분은 약물 발견 및 단백질 구조 예측과 같은 생명 과학에서 딥 러닝의 특정 응용 프로그램에 중점을 둡니다. 세 번째 부분에서는 생명 과학에서 실제 문제를 해결하는 데 딥 러닝을 사용하는 방법을 설명하는 일련의 사례 연구를 제공합니다.
전반적으로 "생명 과학을 위한 딥 러닝"은 생명 과학 문제에 딥 러닝을 적용하는 데 관심이 있는 모든 사람에게 유용한 리소스입니다. 실용적인 접근 방식과 실제 응용 프로그램에 중점을 두어 연구자, 학생 및 실무자 모두에게 유용한 가이드가 됩니다.
- 실습 코드
https://github.com/AcornPublishing/dl-life-sciences
GitHub - AcornPublishing/dl-life-sciences: 생명과학을 위한 딥러닝 [생물학, 유전체학, 신약 개발에 적용하
생명과학을 위한 딥러닝 [생물학, 유전체학, 신약 개발에 적용하는 실무 딥러닝]. Contribute to AcornPublishing/dl-life-sciences development by creating an account on GitHub.
github.com
2. install
- pip install
!pip install --pre deepchem[tensorflow]- version check
import deepchem as dc
dc.__version__3. tutorial (p44-55)
- 기본 데이터셋 만들어 보기
1) library import
import deepchem as dc
import numpy as np2) array 생성
x = np.random.random((4, 5))
y = np.random.random((4, 1))3) array 확인
x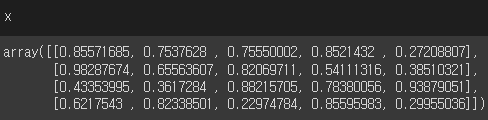
y
4) dataset으로 합쳐주기
dataset = dc.data.NumpyDataset(x,y)5) 생성된 dataset과 array가 같은지 확인해보기
print(np.array_equal(x,dataset.X))
print(np.array_equal(y,dataset.y))
- 독성 분자 예측 모델 만들기
1) import
import numpy as np
import deepchem as dc2) dataset load
tox21_tasks, tox21_datasets, transformers = dc.molnet.load_tox21()3) dataset check
tox21_tasks
tox21_datasetsb
4) train, valid, test dataset
train_dataset, valid_dataset, test_dataset = tox21_datasets5) shape check
train_dataset.X.shape
valid_dataset.X.shape
test_dataset.X.shape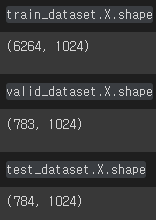
np.shape(train_dataset.y)
np.shape(valid_dataset.y)
np.shape(test_dataset.y)
6) transformers check
transformers
7) model load
model = dc.models.MultitaskClassifier(
n_tasks=12, n_features=1024, layer_sizes=[1000]
)8) model fit
model.fit(train_dataset, nb_epoch=10)
9) metric 계산식 설정
metric = dc.metrics.Metric(dc.metrics.roc_auc_score, np.mean)10) train, test 에서 score 계산
train_scores = model.evaluate(train_dataset, [metric], transformers)
test_scores = model.evaluate(test_dataset, [metric], transformers)11) performance check
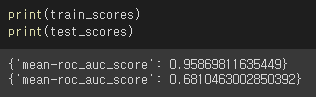
print(train_scores)
print(test_scores)