
- XGBoost 환경 셋팅
#0. tpot and xgboost
#1. cpu : conda install
#2. single gpu : cuml
#3. multi gpu : rapids, conda install tpot and dask_ml
#0 TPOT and XGBoost
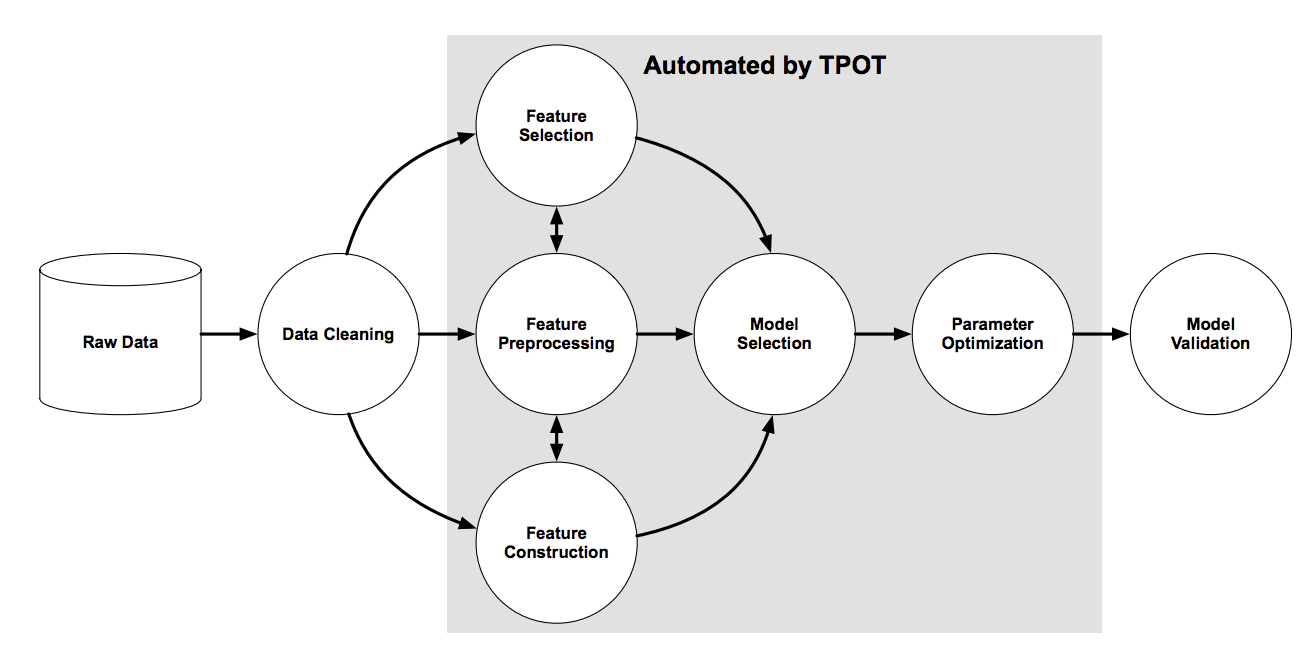
#0.0 TPOT for Automated Machine Learning
Automated Machine Learning (AutoML)
사용자 개입이 거의없이 예측 모델링 작업을 위해 성능이 우수한 모델을 자동으로 검색하는 기술
TPOT
- Python에서 AutoML을 수행하기위한 오픈 소스 라이브러리
- 데이터 변환 및 기계 학습 알고리즘에 인기있는 Scikit-Learn 기계 학습 라이브러리를 사용
- 유전 프로그래밍 확률 적 글로벌 검색 절차를 사용
- 주어진 데이터 세트에 대한 최고 성능의 모델 파이프 라인을 효율적으로 검색
Documents : epistasislab.github.io/tpot/
TPOT
Consider TPOT your Data Science Assistant. TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming. TPOT will automate the most tedious part of machine learning by intelligently exploring thousan
epistasislab.github.io
Tutorial : machinelearningmastery.com/tpot-for-automated-machine-learning-in-python/
TPOT for Automated Machine Learning in Python
Automated Machine Learning (AutoML) refers to techniques for automatically discovering well-performing models for predictive modeling tasks with very little user […]
machinelearningmastery.com
#0.1 XGBoost
XGBoost
- 고도로 효율적이고 유연하며 이식 가능하도록 설계된 최적화 된 분산 그라디언트 부스팅 라이브러리
- Gradient Boosting 프레임 워크에서 기계 학습 알고리즘을 구현
- XGBoost는 많은 데이터 과학 문제를 빠르고 정확하게 해결하는 병렬 트리 부스팅 (GBDT, GBM)을 제공
- 동일한 코드가 주요 분산 환경 (Hadoop, SGE, MPI)에서 실행가능
Documents : xgboost.readthedocs.io/en/latest/
XGBoost Documentation — xgboost 1.5.0-SNAPSHOT documentation
xgboost.readthedocs.io
1. 성능이 우수한 XGBoost 알고리즘을 이용해 machine learning modeling을 하고 싶음
2. 그러나 xgboost의 hyperparameters가 너무 많아 tuning하기 쉽지 않음
3. TPOT을 이용해서 best hyperparameters를 찾아 보자
#1 CPU : conda install
해당 guide에 따라 install : epistasislab.github.io/tpot/installing/
Installation - TPOT
Installation TPOT is built on top of several existing Python libraries, including: Most of the necessary Python packages can be installed via the Anaconda Python distribution, which we strongly recommend that you use. Support for Python 3.4 and below has b
epistasislab.github.io
필자는 conda를 선호
#1.0 TPOT install
conda install -c conda-forge tpot#1.1 XGBoost install
conda install -c conda-forge xgboost
#1.2 config 수정
classifier_config_dict = {
# xgboost just CPU
'xgboost.XGBClassifier': {
'n_estimators': [100, 250 ,500, 750, 1000],
'learning_rate': [1e-2, 1e-1, 0.3],
'max_depth': range(2, 11),
'min_child_weight': range(1, 21),
'gamma':np.arange(0, 1.01, 0.2),
'subsample': np.arange(0.2, 1.01, 0.2),
'colsample_bytree': np.arange(0.4,1.01,0.2),
"reg_alpha": [0, 0.25, 0.5, 0.75, 1],
"reg_lambda": [1, 2, 4, 6, 8],
'scale_pos_weight': [estimate],
'objective': ['binary:logistic'],
'n_jobs': [1],
'verbosity': [0]
},
}XGBoost의 best parameters찾는게 목적 / classifier config만 적당한 변수들로 수정
XGBoost parameter 참고 : xgboost.readthedocs.io/en/latest/parameter.html#
XGBoost Parameters — xgboost 1.5.0-SNAPSHOT documentation
XGBoost Parameters Before running XGBoost, we must set three types of parameters: general parameters, booster parameters and task parameters. General parameters relate to which booster we are using to do boosting, commonly tree or linear model Booster para
xgboost.readthedocs.io
#1.3 Using TPOT
tpot = TPOTClassifier(scoring="roc_auc",
cv=5,
random_state=SEED,
n_jobs=4,
verbosity=3,
generations=100,
population_size=100,
use_dask=False,
warm_start=False,
config_dict=classifier_config_dict,
template='Classifier')
training_features=X_train_features.copy(deep=True)
tpot.fit(training_features, y_train)Parameters 참고 : epistasislab.github.io/tpot/api/
TPOT API - TPOT
Parameters: generations: int or None optional (default=100) Number of iterations to the run pipeline optimization process. It must be a positive number or None. If None, the parameter max_time_mins must be defined as the runtime limit. Generally, TPOT will
epistasislab.github.io
#1.4 export best hyperparameters
tpot.export('model_best_parameters.py')
#2 Single GPU : cuml
#2.0 TPOT-cuml install
conda env create -f tpot-cuml.yml -n tpot-cuml참고 : epistasislab.github.io/tpot/installing/#installation-for-using-tpot-cuml-configuration
Installation - TPOT
Installation TPOT is built on top of several existing Python libraries, including: Most of the necessary Python packages can be installed via the Anaconda Python distribution, which we strongly recommend that you use. Support for Python 3.4 and below has b
epistasislab.github.io
#2.1 config 수정
XGBoost의 tree_method 옵션에 'gpu_hist'를 추가
classifier_config_dict = {
# xgboost tree method = gpu hist
'xgboost.XGBClassifier': {
'n_estimators': [100, 250 ,500, 750, 1000],
'learning_rate': [1e-2, 1e-1, 0.3],
'max_depth': range(2, 11),
'min_child_weight': range(1, 21),
'gamma':np.arange(0, 1.01, 0.2),
'subsample': np.arange(0.2, 1.01, 0.2),
'colsample_bytree': np.arange(0.4,1.01,0.2),
"reg_alpha": [0, 0.25, 0.5, 0.75, 1],
"reg_lambda": [1, 2, 4, 6, 8],
'scale_pos_weight': [estimate],
'objective': ['binary:logistic'],
'tree_method' : ['gpu_hist'],
'n_jobs': [1],
'verbosity': [0]
},
}config 참고 : github.com/EpistasisLab/tpot/blob/master/tpot/config/classifier_cuml.py
EpistasisLab/tpot
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming. - EpistasisLab/tpot
github.com
#2.2 using TPOT and export output
tpot = TPOTClassifier(scoring="roc_auc",
cv=5,
random_state=SEED,
n_jobs=4,
verbosity=3,
generations=100,
population_size=100,
use_dask=False,
warm_start=False,
config_dict=classifier_config_dict,
template='Classifier')
training_features=X_train_features.copy(deep=True)
tpot.fit(training_features, y_train)
tpot.export('model_best_parameters.py')
#3 Multi GPU : rapids, conda install tpot and dask_ml
#3.0 install rapids
참고 : rapids.ai/start.html#get-rapids
Getting Started | RAPIDS
Get started with RAPIDS using conda, docker, or from source builds.
rapids.ai
rapids 페이지 접속 후 버전 클릭 후 COMMAND copy and paste
#3.1 install TPOT
conda install -c conda-forge tpot
#3.2 dask setting
from dask_cuda import LocalCUDACluster
from dask.distributed import Client
# Create a Dask Cluster with one worker per GPU
cluster = LocalCUDACluster()
client = Client(cluster)참고: dask-cuda.readthedocs.io/en/latest/quickstart.html
Quickstart — dask-cuda 0.20.0a+14.g67d536e.dirty documentation
A Dask-CUDA cluster can be created using either LocalCUDACluster or dask-cuda-worker from the command line. dask-cuda-worker To create an equivalent cluster from the command line, Dask-CUDA workers must be connected to a scheduler started with dask-schedul
dask-cuda.readthedocs.io
#3.3 config 수정
XGBoost의 tree_method 옵션에 'gpu_hist'를 추가
classifier_config_dict = {
# xgboost tree method = gpu hist
'xgboost.XGBClassifier': {
'n_estimators': [100, 250 ,500, 750, 1000],
'learning_rate': [1e-2, 1e-1, 0.3],
'max_depth': range(2, 11),
'min_child_weight': range(1, 21),
'gamma':np.arange(0, 1.01, 0.2),
'subsample': np.arange(0.2, 1.01, 0.2),
'colsample_bytree': np.arange(0.4,1.01,0.2),
"reg_alpha": [0, 0.25, 0.5, 0.75, 1],
"reg_lambda": [1, 2, 4, 6, 8],
'scale_pos_weight': [estimate],
'objective': ['binary:logistic'],
'tree_method' : ['gpu_hist'],
'n_jobs': [1],
'verbosity': [0]
},
}#3.3 using TPOT and export output
use_dask=True로 해줘야됨
tpot = TPOTClassifier(scoring="roc_auc",
cv=5,
random_state=SEED,
n_jobs=4,
verbosity=3,
generations=100,
population_size=100,
use_dask=True,
warm_start=False,
config_dict=classifier_config_dict,
template='Classifier')
training_features=X_train_features.copy(deep=True)
tpot.fit(training_features, y_train)
tpot.export('model_best_parameters.py')



