

imbalace dataset을 이용해서 modeling한 classification model에서 predict probabilities를 calibration 해주면 performance의 개선이 있을 수 있음
참고 : machinelearningmastery.com/probability-calibration-for-imbalanced-classification/
How to Calibrate Probabilities for Imbalanced Classification
Many machine learning models are capable of predicting a probability or probability-like scores for class membership. Probabilities provide a required level of granularity for evaluating and comparing models, especially on imbalanced classification problem
machinelearningmastery.com
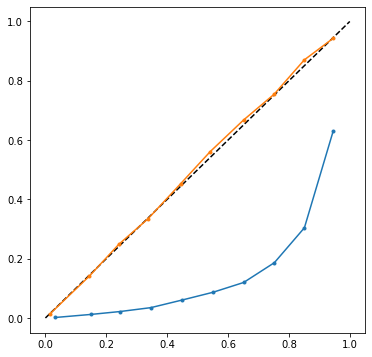
imbalance classification model의 calibration curve를 그려보면 보통 파란색선과 같은 '┘'자 형태의 curve가 그려짐 대각선과 유사한 주황색선으로 calibrating을 해보자
#1. calibrating predict probability : plot only calibrated model
method에는 크게 두가지 'sigmoid', 'isotonic'이 있음
from xgboost import XGBClassifier
from sklearn.calibration import CalibratedClassifierCV
from sklearn.calibration import calibration_curve
#calibrated model
#model
model_c1 = XGBClassifier()
# fit a model
calibrated = CalibratedClassifierCV(model_c1, method='isotonic', cv=5)
calibrated.fit(X_train_features, y_train)
# predict probabilities
train_probs = calibrated.predict_proba(X_train_features)[:, 1]
# reliability diagram
fop, mpv = calibration_curve(y_train, train_probs, n_bins=10)
# plot perfectly calibrated
plt.plot([0, 1], [0, 1], linestyle='--')
# plot calibrated reliability
plt.plot(mpv, fop, marker='.')
plt.rcParams["figure.figsize"] = (6,6)
plt.show()
#2. plot both calibrated model and uncalibrated model
#uncalibrated and calibrated plot
# predict uncalibrated probabilities
def uncalibrated(trainX, trainy):
# fit a model
model_c2 = XGBClassifier()
model_c2.fit(trainX, trainy)
# predict probabilities
return model_c2.predict_proba(trainX)[:, 1]
# predict calibrated probabilities
def calibrated2(trainX, trainy):
# define model
model_c3 = XGBClassifier().fit(X_train_features, y_train)
# define and fit calibration model
calibrated_c3 = CalibratedClassifierCV(model_c3, method='isotonic', cv=5)
calibrated_c3.fit(trainX, trainy)
# predict probabilities
return calibrated_c3.predict_proba(trainX)[:, 1]
# uncalibrated predictions
yhat_uncalibrated = uncalibrated(X_train_features, y_train)
# calibrated predictions
yhat_calibrated = calibrated2(X_train_features, y_train)
# reliability diagrams
fop_uncalibrated, mpv_uncalibrated = calibration_curve(y_train, yhat_uncalibrated, n_bins=10)
fop_calibrated, mpv_calibrated = calibration_curve(y_train, yhat_calibrated, n_bins=10)
# plot perfectly calibrated
plt.plot([0, 1], [0, 1], linestyle='--', color='black')
# plot model reliabilities
plt.plot(mpv_uncalibrated, fop_uncalibrated, marker='.')
plt.plot(mpv_calibrated, fop_calibrated, marker='.')
plt.rcParams["figure.figsize"] = (6,6)
plt.show()
참고 : machinelearningmastery.com/calibrated-classification-model-in-scikit-learn/
How and When to Use a Calibrated Classification Model with scikit-learn
Instead of predicting class values directly for a classification problem, it can be convenient to predict the probability of an observation belonging to each possible class. Predicting probabilities allows some flexibility including deciding how to interpr
machinelearningmastery.com
#3. testset에서 calibration plot을 좀 더 자세히 그려보면
# Create classifiers
xgb = model
xgb_calibrated = calibrated
# #############################################################################
# Plot calibration plots
plt.figure(figsize=(10, 10))
ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)
ax2 = plt.subplot2grid((3, 1), (2, 0))
ax1.plot([0, 1], [0, 1], "k:", label="Perfectly calibrated")
for clf, name in [(xgb, 'XGBoost'),
(xgb_calibrated, 'calibrated XGBoost')]:
clf.fit(X_test_features, y_test)
if hasattr(clf, "predict_proba"):
prob_pos = clf.predict_proba(X_test_features)[:, 1]
else: # use decision function
prob_pos = clf.decision_function(X_test_features)
prob_pos = \
(prob_pos - prob_pos.min()) / (prob_pos.max() - prob_pos.min())
fraction_of_positives, mean_predicted_value = \
calibration_curve(y_test, prob_pos, n_bins=20)
ax1.plot(mean_predicted_value, fraction_of_positives, "s-",
label="%s" % (name, ))
ax2.hist(prob_pos, range=(0, 1), bins=20, label=name,
histtype="step", lw=2)
ax1.set_ylabel("Fraction of positives")
ax1.set_ylim([-0.05, 1.05])
ax1.legend(loc="lower right")
ax1.set_title('Calibration plots (reliability curve)')
ax2.set_xlabel("Mean predicted value")
ax2.set_ylabel("Count")
ax2.legend(loc="upper center", ncol=2)
plt.tight_layout()
plt.show()
Probability Calibration curves — scikit-learn 0.24.1 documentation
Note Click here to download the full example code or to run this example in your browser via Binder Probability Calibration curves When performing classification one often wants to predict not only the class label, but also the associated probability. This
scikit-learn.org
결과적으로 calibrated model의 성능이 미세하게 개선(특히 sensitivity가)되긴 함.