[Graph DB] Neo4j를 활용한 그래프 데이터 탐색적 데이터 분석(EDA) 가이드 (고급)
목차
Cypher
// 가장 흔한 진단-약물 조합 찾기
MATCH (p:Person)-[:HAS_CONDITION_OCCURRENCE]->(c:ConditionOccurrence)
MATCH (p)-[:HAS_DRUG_EXPOSURE]->(d:DrugExposure)
WHERE c.condition_start_date <= d.drug_exposure_start_date
RETURN c.condition_concept_name as Condition,
d.drug_concept_name as Drug,
count(*) as Frequency
ORDER BY Frequency DESC
LIMIT 10;
// 환자별 방문 횟수 분포
MATCH (p:Person)-[:HAS_VISIT_OCCURRENCE]->(v:VisitOccurrence)
WITH p, count(v) as visit_count
RETURN visit_count, count(p) as patient_count
ORDER BY visit_count;
// 특정 조건에서 시작하여 약물 처방까지의 경로
MATCH path = (p:Person)-[:HAS_CONDITION_OCCURRENCE]->(c:ConditionOccurrence)
-[:ASSOCIATED_DURING_VISIT]->(v:VisitOccurrence)
<-[:ASSOCIATED_DURING_VISIT]-(d:DrugExposure)
WHERE c.condition_concept_name = "Asthma"// "Gastritis" "Asthma" "Acute bronchitis"
RETURN path
LIMIT 5;
// 자주 함께 발생하는 질병 쌍 찾기
MATCH (p:Person)-[:HAS_CONDITION_OCCURRENCE]->(c1:ConditionOccurrence)
MATCH (p)-[:HAS_CONDITION_OCCURRENCE]->(c2:ConditionOccurrence)
WHERE id(c1) < id(c2)
WITH c1.condition_concept_name as Condition1,
c2.condition_concept_name as Condition2,
count(*) as Frequency
WHERE Frequency > 10
RETURN Condition1, Condition2, Frequency
ORDER BY Frequency DESC
LIMIT 15;
// 조건 발생 후 처방까지 걸리는 평균 시간
MATCH (p:Person)-[:HAS_CONDITION_OCCURRENCE]->(c:ConditionOccurrence)
MATCH (p)-[:HAS_DRUG_EXPOSURE]->(d:DrugExposure)
WHERE c.condition_start_date <= d.drug_exposure_start_date
WITH c.condition_concept_name as Condition,
d.drug_concept_name as Drug,
duration.between(date(c.condition_start_date), date(d.drug_exposure_start_date)).days as Days
RETURN Condition, Drug, avg(Days) as AvgDaysToTreatment
ORDER BY AvgDaysToTreatment
LIMIT 10;
// 특정 조건을 가진 환자들의 측정값 추이
MATCH (p:Person)-[:HAS_CONDITION_OCCURRENCE]->(c:ConditionOccurrence)
MATCH (p)-[:HAS_MEASUREMENT]->(m:Measurement)
WHERE c.condition_concept_name = "특정 질병명"
RETURN m.measurement_concept_name as Measurement,
avg(m.value_as_number) as AvgValue,
min(m.value_as_number) as MinValue,
max(m.value_as_number) as MaxValue
ORDER BY AvgValue DESC;
// 특정 조건에 대한 약물 처방 시퀀스
MATCH (p:Person)-[:HAS_CONDITION_OCCURRENCE]->(c:ConditionOccurrence)
MATCH (p)-[:HAS_DRUG_EXPOSURE]->(d:DrugExposure)
WHERE c.condition_concept_name = "Asthma"
WITH p, c, collect(d.drug_concept_name) as DrugSequence
RETURN DrugSequence, count(*) as Frequency
ORDER BY Frequency DESC
LIMIT 10;
// 가장 많은 연관 관계를 가진 질병 찾기
MATCH (c:ConditionOccurrence)<-[:HAS_CONDITION_OCCURRENCE]-(p:Person)
-[:HAS_CONDITION_OCCURRENCE]->(c2:ConditionOccurrence)
WHERE id(c) < id(c2)
WITH c.condition_concept_name as Condition, count(DISTINCT c2) as Connections
RETURN Condition, Connections
ORDER BY Connections DESC
LIMIT 10;
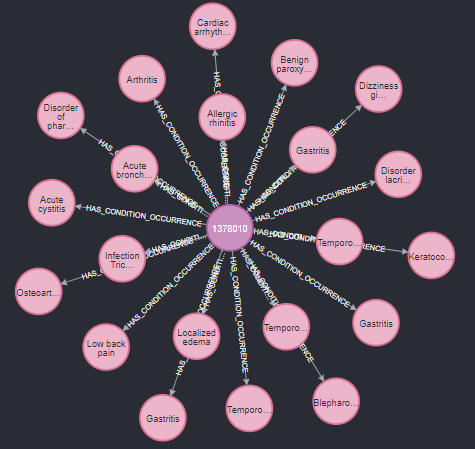
//환자의 질병 경과 분석:
//특정 환자에 대해 시간 순서대로 질병 발생 및 치료 경과를 추적합니다.
MATCH p=(person:Person)-[:HAS_CONDITION_OCCURRENCE]->(condition:ConditionOccurrence)
WHERE person.person_id = '1378010'
WITH p, condition.condition_start_date AS startDate
ORDER BY startDate
RETURN p, startDate
//환자의 질병 경과 분석:
//특정 환자에 대해 시간 순서대로 질병 발생 및 치료 경과를 추적합니다.
MATCH p=(person:Person)-[:HAS_CONDITION_OCCURRENCE]->(condition:ConditionOccurrence)
WHERE person.person_id = '1378010'
WITH p, condition.condition_start_date AS startDate
ORDER BY startDate
RETURN p, startDate
//특정 질병과 관련된 약물 분석:
//특정 질병을 가진 환자들이 어떤 약물을 복용했는지 분석합니다.
MATCH p=(person:Person)-[:HAS_CONDITION_OCCURRENCE]->(condition:ConditionOccurrence)-[:ASSOCIATED_DURING_VISIT]->(visit:VisitOccurrence)<-[:ASSOCIATED_DURING_VISIT]-(drug:DrugExposure)
WHERE condition.condition_concept_id = '201340'
RETURN person.person_id, condition.condition_concept_name, drug.drug_concept_name, count(*) AS count
ORDER BY count DESC
// 특정 약물의 부작용 분석:
// 특정 약물을 복용한 환자들에게 어떤 부작용이 발생했는지 분석합니다. (OMOP-CDM에서 부작용 정보를 어떻게 표현했는지에 따라 쿼리가 달라질 수 있습니다. 아래는 예시이며, 실제 데이터에 맞게 수정해야 합니다.)
MATCH p=(person:Person)-[:HAS_DRUG_EXPOSURE]->(drug:DrugExposure)-[:ASSOCIATED_DURING_VISIT]->(visit:VisitOccurrence)<-[:ASSOCIATED_DURING_VISIT]-(condition:ConditionOccurrence)
WHERE drug.drug_concept_id = '19106160' // 19106160 42960914
RETURN person.person_id, drug.drug_concept_name, condition.condition_concept_name, count(*) AS count
ORDER BY count DESC
//DrugID top10
//MATCH (d:DrugExposure)
//RETURN d.drug_concept_id AS DrugID, count(*) AS PreㄱscriptionCount
//ORDER BY PrescriptionCount DESC
//LIMIT 10
Python
# 필요한 라이브러리 임포트
from neo4j import GraphDatabase
# Neo4j 연결 정보 설정
uri = "bolt://localhost:7687" # Neo4j 인스턴스 주소
username = "neo4j" # 사용자 이름
password = "your_password" # 비밀번호
database = "omoptograph"
# Neo4j 드라이버 생성
driver = GraphDatabase.driver(uri, auth=(username, password))
# 쿼리를 실행하고 결과를 반환하는 함수
def run_query(query):
with driver.session() as session:
result = session.run(query)
return [record for record in result]
# 1. 각 노드 유형별 노드 수 계산
query_node_counts = """
MATCH (n)
UNWIND labels(n) AS label
RETURN label, count(*) AS Count
ORDER BY Count DESC
"""
node_counts = run_query(query_node_counts)
print("노드 유형별 노드 수:")
for record in node_counts:
print(f"{record['label']}: {record['Count']}개")
# 2. 각 관계 유형별 관계 수 계산
query_relationship_counts = """
MATCH ()-[r]->()
RETURN type(r) AS RelationshipType, count(*) AS Count
ORDER BY Count DESC
"""
relationship_counts = run_query(query_relationship_counts)
print("\n관계 유형별 관계 수:")
for record in relationship_counts:
print(f"{record['RelationshipType']}: {record['Count']}개")
# 3. 환자당 평균 방문 수 계산
query_avg_visits = """
MATCH (p:Person)
RETURN avg(size((p)-[:HAS_VISIT]->())) AS AvgVisitsPerPerson
"""
avg_visits = run_query(query_avg_visits)
print(f"\n환자당 평균 방문 수: {avg_visits[0]['AvgVisitsPerPerson']:.2f}회")
# 4. 가장 흔한 상위 10개 질병
query_top_conditions = """
MATCH (c:ConditionOccurrence)
RETURN c.condition_concept_id AS ConditionID, count(*) AS Count
ORDER BY Count DESC
LIMIT 10
"""
top_conditions = run_query(query_top_conditions)
print("\n가장 흔한 상위 10개 질병:")
for record in top_conditions:
print(f"질병 ID {record['ConditionID']}: {record['Count']}건")
# 5. 가장 많은 환자에게 영향을 미친 질병
query_condition_distribution = """
MATCH (p:Person)-[:HAS_CONDITION_OCCURRENCE]->(c:ConditionOccurrence)
RETURN c.condition_concept_id AS ConditionID, count(DISTINCT p) AS NumPersons
ORDER BY NumPersons DESC
LIMIT 10
"""
condition_distribution = run_query(query_condition_distribution)
print("\n가장 많은 환자에게 영향을 미친 질병:")
for record in condition_distribution:
print(f"질병 ID {record['ConditionID']}: {record['NumPersons']}명")
# 6. 질병의 동시 발생 분석
query_condition_cooccurrence = """
MATCH (p:Person)-[:HAS_CONDITION_OCCURRENCE]->(c1:ConditionOccurrence)
MATCH (p)-[:HAS_CONDITION_OCCURRENCE]->(c2:ConditionOccurrence)
WHERE c1.condition_concept_id < c2.condition_concept_id
RETURN c1.condition_concept_id AS Condition1, c2.condition_concept_id AS Condition2, count(DISTINCT p) AS NumPersons
ORDER BY NumPersons DESC
LIMIT 10
"""
condition_cooccurrence = run_query(query_condition_cooccurrence)
print("\n동시 발생 상위 10개 질병 쌍:")
for record in condition_cooccurrence:
print(f"질병 {record['Condition1']} & {record['Condition2']}: {record['NumPersons']}명")
# 7. 환자당 평균 검사 수 계산
query_avg_measurements = """
MATCH (p:Person)
RETURN avg(size((p)-[:HAS_MEASUREMENT]->())) AS AvgMeasurementsPerPerson
"""
avg_measurements = run_query(query_avg_measurements)
print(f"\n환자당 평균 검사 수: {avg_measurements[0]['AvgMeasurementsPerPerson']:.2f}회")
# 8. 가장 흔한 상위 10개 시술
query_common_procedures = """
MATCH (proc:ProcedureOccurrence)
RETURN proc.procedure_concept_id AS ProcedureID, count(*) AS Count
ORDER BY Count DESC
LIMIT 10
"""
common_procedures = run_query(query_common_procedures)
print("\n가장 흔한 상위 10개 시술:")
for record in common_procedures:
print(f"시술 ID {record['ProcedureID']}: {record['Count']}건")
# 9. 처방된 약물 분포
query_drug_exposures = """
MATCH (d:DrugExposure)
RETURN d.drug_concept_id AS DrugID, count(*) AS Count
ORDER BY Count DESC
LIMIT 10
"""
drug_exposures = run_query(query_drug_exposures)
print("\n가장 많이 처방된 상위 10개 약물:")
for record in drug_exposures:
print(f"약물 ID {record['DrugID']}: {record['Count']}건")
# 10. 성별에 따른 질병 분포
query_gender_conditions = """
MATCH (p:Person)-[:HAS_Gender]->(g:Gender),
(p)-[:HAS_CONDITION_OCCURRENCE]->(c:ConditionOccurrence)
RETURN g.gender_concept_id AS GenderID, c.condition_concept_id AS ConditionID, count(*) AS Count
ORDER BY Count DESC
LIMIT 10
"""
gender_conditions = run_query(query_gender_conditions)
print("\n성별에 따른 상위 질병:")
for record in gender_conditions:
print(f"성별 ID {record['GenderID']}, 질병 ID {record['ConditionID']}: {record['Count']}건")
# 드라이버 연결 종료
driver.close()