
if(kakao) 2024 행사 요약
행사 개요:
- 카카오 그룹의 기술 비전 공유 및 기술적 성취를 개발자 커뮤니티와 공유하는 카카오 대표 개발자 컨퍼런스.
- 오프라인 중심 운영, 주요 세션 온라인 실시간 스트리밍 및 다시보기 제공.
- 무료 참가.
참가 신청:
- 기간: 9/30(월) ~ 10/9(수)
- 방법: if kakao 카카오톡 채널 챗봇을 통해 신청 (카카오 계정 및 카카오톡 앱 필요)
- 대상: 카카오 기술에 관심 있는 누구나 (만 18세 이상, 미성년자는 부모 동의 필요)
- 신청 가능 일자: 3일 모두 가능하나, 최종 1일 참가 확정.
- 티켓 양도 불가.
- 참가 확정 안내: 10/16(수), if kakao 카카오톡 채널 통해 안내.
행사 당일:
- 점심 식사 및 오후 간식 제공.
- 주차 불가 (셔틀버스 이용 권장: 양재역, 판교역 출발, 자세한 내용 별도 안내).
- 판교역 - 카카오 AI 캠퍼스 간 순환버스 운행 (9:10 ~ 09:40 10분 간격, 12:40~18:00 20분 간격).
- 무료 Wi-Fi 제공.
- 문의: if2024@kakao.com
kakao AI campus
카카오AI캠퍼스 : 네이버
블로그리뷰 15
m.place.naver.com
Day 1 참여내용
세션 시간표


Keynote
- 모든 연결을 새롭게 / 정신아 (카카오)
- AI 서비스 - Model Orchestration: 내부모델, 오픈소스 모델, 비공개 모델 모두 활용
- Team kanana
- AI 모델 / 서비스 전담 조직
- kanana: 관계기반 AI 신규 서비스
- kanana_ : GenAI 모델
- AI mate: 카나, 나나
- AI 금융전문가
- 카카오페이 MoE (보험, 부동산, 자산, 투자, 세무)
- AI 보험 관리사
- 건강 검진 데이터 연결하여 적절한 보험 매칭
- AI 기반 자율주행 택시
- 중앙 관제 시스템
- AI Safety
- Kakao AI Safety Initiative
- SafeGuard by Kanana
- 태스크 카테고리에 따른 정책 및 대화를 비교하여 결과 생성

- 태스크 카테고리에 따른 정책 및 대화를 비교하여 결과 생성
- AI model

- AI Architecture & deploy

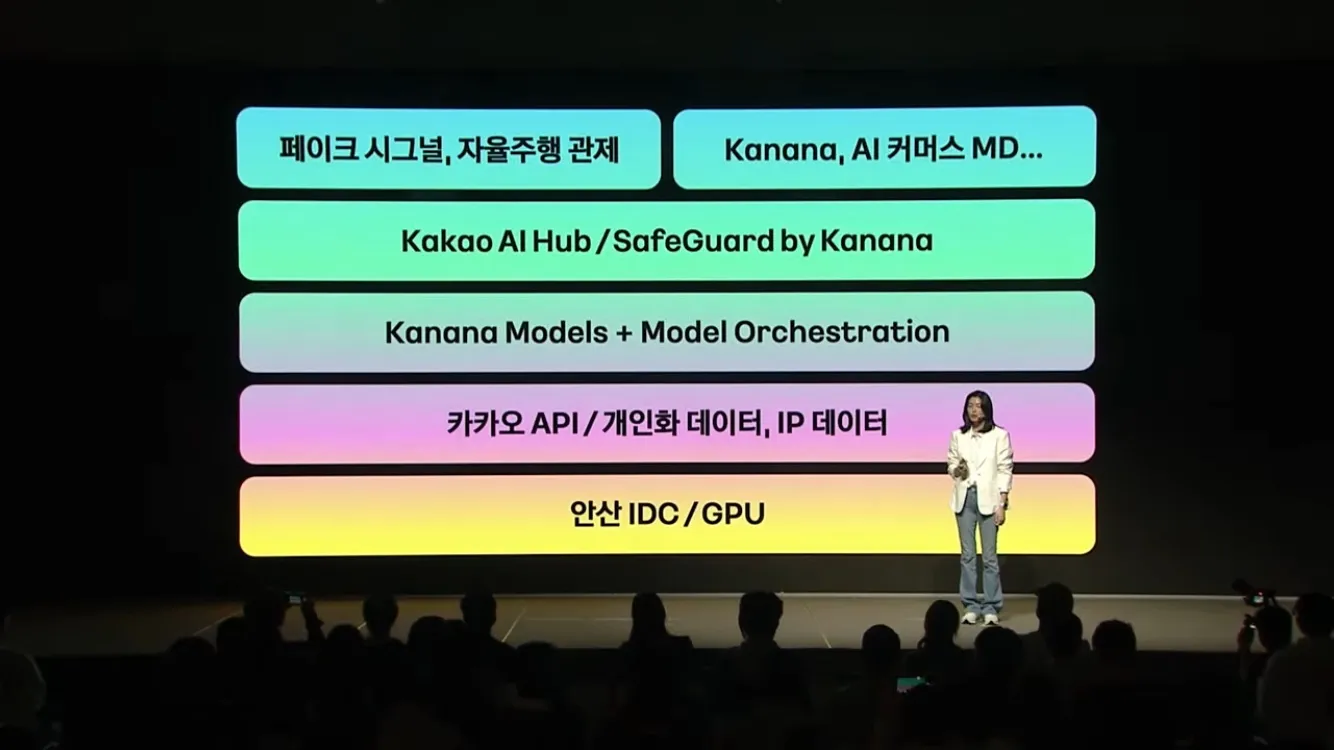
- AI mate와의 새로운 연결 Kanana / 이상호 (카카오)
- 카카오톡과 구분하여 별도의 앱으로 운영

- 개인 메이트: 나나, 그룹 메이트: 카나

- Context input & Memory & Personalized Output → 가장 ‘나’다운 AI
- 대화 내용은 암호화 작업을 거쳐 서버에 저장 → device 변경 시 대화 내용 백업 가능
- 카카오톡과 구분하여 별도의 앱으로 운영
이미지까지 이해하는 Multimodal LLM의 학습 방법 밝혀내기 / 강우영 (카카오브레인)
- Multimodal Large Language Models (MLLMs)

- Honeybee paper (HIghlight)
- 목표: 이미지와 텍스트를 함께 이해하는 AI 모델 개발.
- 핵심 기술: Locality-enhanced Projector. 시각 정보를 언어 모델에 효과적으로 전달. 공간적 정보 이해, 모델 효율성 향상.
- 아키텍처:
- Vision Encoder: 이미지를 벡터로 변환 (CLIP, SigLIP 등).
- Projector: 시각 정보를 언어 모델에 연결 (Locality-enhanced Projector).
- Large Language Model: 텍스트 이해 및 생성 (LLaMA, Vicuna, Qwen 등).
- 학습 방법: Visual Instruction Tuning
- 핵심: 다양한 시각적 지시사항 활용, 이미지-텍스트 연결 능력 향상.
- 전략:
- 데이터셋 혼합: 다양한 데이터셋/작업 유형 혼합 학습 (VQA, Captioning, Retrieval 등). 폭넓은 능력 확보.
- 데이터셋 균형: 데이터셋 간 균형 유지, 일반화 성능 향상.
- 템플릿 디자인: 데이터셋별 세분화된 템플릿, 효과적 학습 유도.
- 멀티턴 & 중복 제거: 대화형 멀티턴 템플릿, 중복 데이터 제거. 학습 효율 증대.
- GPT 활용: GPT로 텍스트 데이터 생성 (상세 설명, 질문 등). 풍부한 학습 데이터 확보.전략 MMB SEED-I MME-P 평균
단일 데이터셋 65.5 60.2 1480.5 67.1 혼합 데이터셋 69.2 64.2 1568.2 70.6 - (표 1) 데이터셋 혼합 전략에 따른 성능 비교 (예시)
- 성능:
- 비교 대상: 기존 SOTA MLLM (MiniGPT-4, BLIP-2, LLaVA-1.5 등).
- 결과: 다양한 벤치마크에서 우수한 성능. 복잡한 추론 능력 탁월.모델 MMB SEED-I MME-P LLaVA-w
MiniGPT-4 - 1158.7 - - BLIP-2 - 1504.6 - 58.2 LLaVA-1.5 67.7 1826.7 - 70.7 Honeybee 73.5 1950.0 - 72.9 - (표 2) 다른 MLLM과의 성능 비교 (Vicuna 13B 기반)
- Kanana-v: Honeybee의 진화
- 특징: 더 큰 데이터셋, 고해상도 이미지 학습. 성능 향상.
- 비교 대상: 최신 MLLM (GPT-4V, Gemini-Pro 등).
- 결과: 경쟁력 있는 성능.모델 MMB ChartQA DocVQA InfoVQA MathVista SEED-i MMMU
GPT-4V 77 78.5 88.4 75.1 49.9 69.1 56.8 Gemini-Pro 73.6 74.1 88.1 75.2 45.2 70.7 47.9 Honeybee 70.1 - - - - 64.5 35.3 Kanana-v 80.5 83.2 92.6 72.9 62.1 74.7 47.6 - (표 3) Kanana-v와 최신 MLLM 성능 비교
- 기능 예시:
- 상세 캡션 생성: 빈티지 트럭 사진을 입력하고 "이 이미지에 대해 자세히 설명해줘"라고 요청하면, Honeybee는 "여러 남성이 빨간 클래식 트럭 주위에 모여있고, 트럭은 광택이 나는 크롬 그릴과 헤드라이트가 있으며, 1950년대 또는 1960년대 스타일입니다. 남성들은 티셔츠와 청바지를 입고 트럭을 살펴보고 있는 것 같습니다. 배경에는 'Super Fresh'라는 간판이 있는 건물이 있습니다." 와 같이 매우 상세한 묘사를 생성합니다.
- 질의응답: 다양한 품종의 소들이 있는 이미지를 보여주고 "이 이미지에서 뿔이 있는 소는 몇 마리입니까?"라고 질문하면 Honeybee는 이미지를 분석하여 "이 이미지에는 뿔이 있는 소가 세 마리 있습니다."라고 답합니다.
- 수학 문제 풀이: 삼각형 그림과 함께 "삼각형의 넓이를 구하시오. 밑변은 10cm, 높이는 5cm입니다." 라는 질문을 입력하면, Honeybee는 "삼각형의 넓이는 (밑변 x 높이) / 2 이므로, (10cm x 5cm) / 2 = 25cm² 입니다." 라고 답합니다.
- 피드백: LLM 관련 업무 중 multi-modal 필요시 (특히 이미지) Honeybee 기술 고려 가능
그래프 기반 악성 유저군 탐지: 온라인 광고 도메인에서의 적용 / 변장현 (카카오)
- 목표: 온라인 광고 생태계 교란하는 악성 유저를 효과적으로 탐지.
- 방법: 그래프 기반 접근법 활용. 온라인 광고 도메인 실제 적용 사례 중심 설명.

1. 매체-매체 그래프 구축
- 관찰: 악성 유저는 여러 매체를 통해 조직적 활동.
- 해결책: 유저 활동 로그 기반 매체-매체 그래프 구축.
- 노드: 매체
- 엣지: 두 매체 간 유저 중복 활동 존재 여부
- 효과: 매체 간 연관성 파악, 악성 유저 활동 패턴 시각적 분석 가능.
- 사용 도구:
- 전처리: 도메인 지식 활용.
- 그래프 생성 및 분석: Apache Spark GraphFrames.
- 시각화: Gephi.
2. 커뮤니티 탐지 알고리즘: SCC (Strongly Connected Component)

- 가정: 악성 유저는 그래프 내 밀접하게 연결된 커뮤니티 형성.
- 알고리즘: SCC 활용. 그래프 내 모든 노드 상호 도달 가능한 부분 그래프 탐색.
- 개선: 시간 복잡도 O(n^2) 에서 O(n) 으로 감소. 대규모 데이터 처리 효율 증대.
- 절차:
- 원본 로그 분석: 유저-매체 상호작용 정보 추출.
- 매체-매체 그래프 생성.
- 커뮤니티 탐지: SCC 알고리즘 적용.
- 어뷰저 필터링: 악성 유저 의심 그룹 분류.
3. 악성 커뮤니티 분류 기준

- 기준 1: 커뮤니티 내부 연결 강도 (Connectivity): 악성 커뮤니티는 높은 내부 연결 강도.
- 기준 2: 정상 유저 방문 확률 (Personalized PageRank): 악성 커뮤니티는 낮은 정상 유저 방문 확률.
- 기준 3: 이웃 매체 간 연결 강도 (Clustering Coefficient): 악성 커뮤니티 구성 매체의 이웃 매체 간 연결 강도 높음.
- 판별: 악성 커뮤니티는 세 기준 모두 높은 값. 일반 커뮤니티는 아님.
4. 결론 및 확장 가능성1. 매체-매체 그래프 구축
- 결론: 그래프 기반 접근법, SCC 알고리즘, 세 가지 분류 기준으로 온라인 광고 악성 유저 효과적 탐지 가능.
- 확장: "유저-매체" 관계를 다른 관계(e.g., "유저-상품")로 변환하여 다른 도메인 적용 가능. (e.g., 이커머스 허위 리뷰 탐지)
- 향후 과제: 지속적인 연구 개발 필요. 진화하는 악성 행위 대응, 건전한 온라인 생태계 구축 기여.
피드백: 의료 또는 보험 쪽에서 활용 가능한 부분 → 보험 사기, 약물(마약류) 오남용
생성형 AI를 활용한 개체명 인식(NER) / 성기훈 (카카오헬스케어)
- 목표: 헬스케어 데이터와 실제 데이터(Real-world Evidence, RWE)에서 생성형 AI를 활용하여 개체명 인식(NER) 성능 향상.
- 기존 NER 방식의 한계:
- Human-labor 방식: 시간 소모 많고, 비용 부담 높음. 오류 발생 가능성.
- LLM 기반 NER: 처리 속도, 비용, 성능 면에서 human-labor 방식 대비 효율적.
처리 속도 144초/건 (200건/일 처리 기준) 2~15초/건 (H100 GPU 개수 18장 기준) 약 10~80배 소요 시간 500일 17.4일 (Max. 15초/건 기준) 약 30배 감소 비용 약 7천6백만원 약 2백만원 (인건비 월 400만원/명 기준) 약 97.5% 감소 성능 평균 85% (human-error 기준) 90% 이상 (F1-score 기준) 약 5% 향상 - LLM 기반 NER 프레임워크

- 데이터 흐름: 파일 서버(Raw Data) → 접근 통제 → Workstation (샘플링, 라벨 스튜디오, 프롬프트 관리, 성능 평가) → LLM 서버 (Foundation Model, Fine-tuned Model) → 추론 결과.
- 단계별 작업:

- 준비 단계: 기록지 선정 및 통합, 데이터 정의서 작성.
- 어노테이션 단계: 데이터 전처리, 랜덤 샘플링, Few-shot 및 테스트 데이터 준비, 어노테이션.
- 성능 고도화 단계: 프롬프트 개선, Fine-tuning.
- 추론 단계: 추론 수행.
- 주요 구성 요소:
- 데이터 정의서: NER 작업에 필요한 정보 정의 (개체명, 위치, 크기, 관련 소견, 시간 변화 등).

- Prompt Manager: LLM에 입력할 프롬프트 생성 및 관리. Few-shot 예시 포함.

- Sampler: 학습 데이터 샘플링. 무작위 추출, 긴 내용 추출, 중복 제외 추출 등 다양한 옵션 제공.

- Annotation Tool (Label Studio): 데이터 어노테이션 작업 수행.
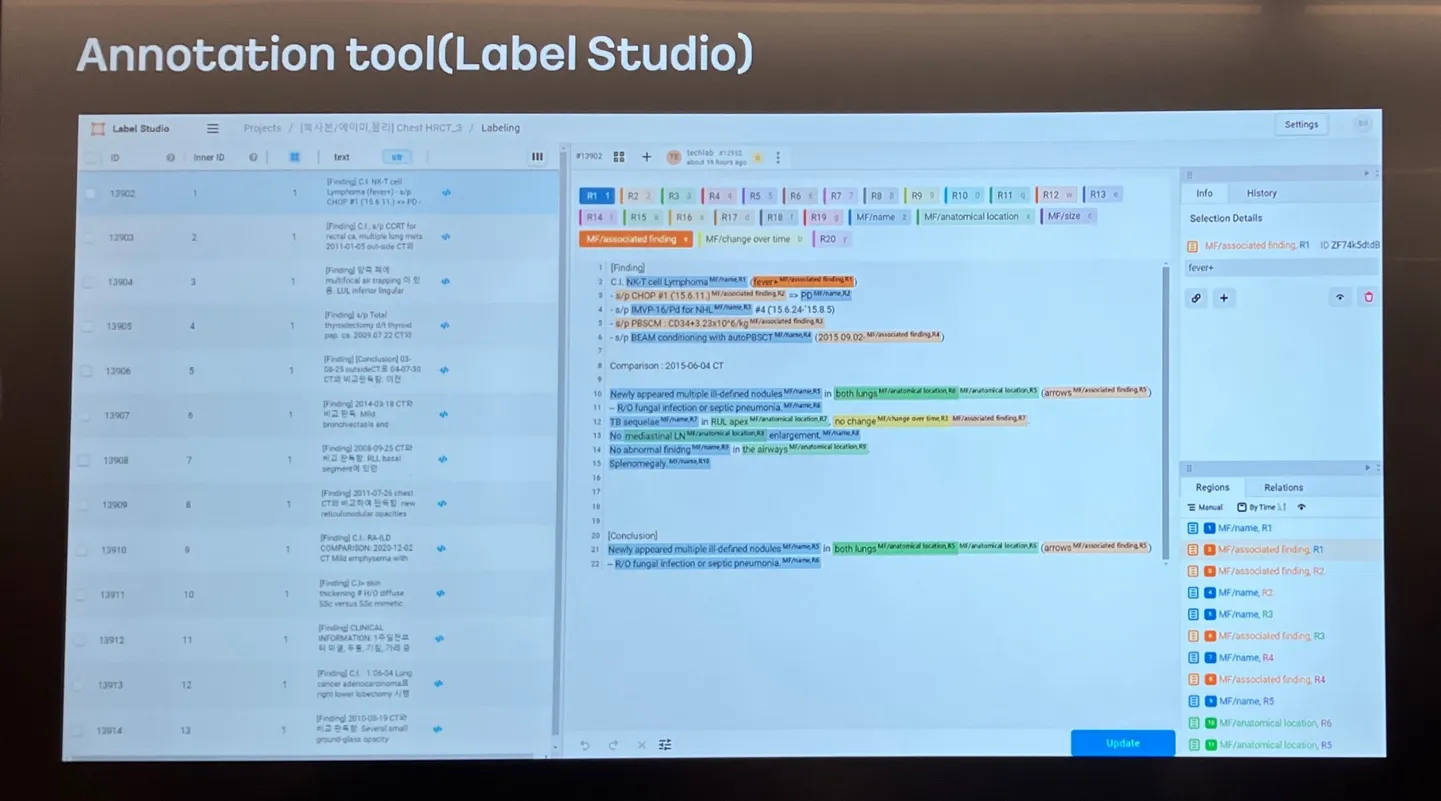
- Result Template & Metric: 결과 JSON 형식 정의 및 성능 평가 지표 (Accuracy, Recall, Precision, F1-score).

- 데이터 정의서: NER 작업에 필요한 정보 정의 (개체명, 위치, 크기, 관련 소견, 시간 변화 등).
- Entity Matching:
- 유사도 측정: Jaccard Similarity Index 사용.
- 가중치 설정: 정보 중요도에 따라 가중치 부여 (1~10). Name에 높은 가중치.
- Threshold 설정: 유사도 0.3 이상만 매칭.
- Experiment (실험):
- 목적: 최적의 성능 조합 탐색 (모델, 파라미터, Few-shot, Fine-tuning 등).
- 핵심 질문: Fine-tuning 데이터 양과 질의 관계.
- 현재까지 밝혀진 사실:
- Prompt 없이 Fine-tuning하는 것이 효율적.
- Fine-tuned 모델에 Few-shot 추가 시 준수한 성능.
- Future Works:
- 성능 향상: 전처리 개선, Report Integration, Sampling, Global Prompt Engineering 등.
- 자동화: 일일 증분 로딩, 모니터링, Report Pattern Classifier, 자동 어노테이션 등.
- 결론:
- 생성형 AI 기반 NER 프레임워크는 헬스케어 데이터 분석에 효율적인 도구. 지속적인 연구 개발을 통해 성능 향상 및 자동화 목표.
- 피드백: NER에 LLM 활용하여 비용 절감, 개발 단계에서 인프라 활용 좋음, 데이터 샘플링의 중요성, 가장 최신의 LLM 성능이 가장 월등
공공데이터를 활용한 RAG 기술 구현 및 프레임워크 소개 / 김도윤 (카카오엔터프라이즈)
목표: 공공데이터 활용 Retrieval-Augmented Generation (RAG) 기술 구현 및 프레임워크 소개. 효율적인 청킹(Chunking) 전략 및 검색 기능 구현.
1. Chunking이란?
- Miller's Law (7±2 법칙): 평균적인 사람의 단기 기억 한계는 7±2개 항목. 기억 단위: Chunk.
- Chunk: 주어진 텍스트에서 인식 가능한 최대 의미 단위. 길이는 사람마다 다름 (숫자, 단어, 구절 등).
- 컴퓨터에서의 Chunking: 텍스트를 의미 단위로 분할하여 효율적인 정보 검색 및 처리 가능.
2. Chunking 방법:
- Fixed-size Chunking: 고정된 크기로 텍스트 분할. 단순하지만 문맥 훼손 가능성.
- Recursive Chunking: 구분자 기반, 계층적/반복적 분할.
- Document Specific Chunking: 문서 구조(Markdown, HTML 등) 활용.
- Semantic Chunking: 의미 기반 분할. 검색 품질 높지만 처리 속도 느림.
- Agentic Chunking: 사람처럼 문맥 이해하여 분할. 첫 문장 기준으로 다음 문장 병합 여부 결정.
(표 1) Chunking 방법 비교
검색 방식 Static Dynamic
| Lexical (문서 단위) | 균등 분할 | Highlight 영역 주변 텍스트 |
| Semantic (Vector) | Fixed Length, Text Overlap | (토큰 단위 임베딩 필요: CoIBERT) |
| 현재 | 의미 분할 (문장 단위, 벡터 유사도) |
3. Chunking API:
- Semantic Chunking 사용: ELECTRA 임베딩, 문장 단위 연산.
- 로직: 유사도 및 유사도 변화율 감지. 의미 변화율 기반 Overlap 적용.
- 학습 데이터: 공공데이터 및 오픈소스 데이터.
4. Chunk Retrieval:
- Chunk Title: 검색 품질에 중요한 요소. 문서 제목 또는 요약 task 변형으로 생성 (T5 훈련).
- Candidate Questions: Chunk 관련 질문 후보 생성. T5 모델 활용.
- Hybrid Retrieval: Chunk 장단점(Focused Topic, Lost Context) 고려. Meta Chunk(요약, 지식 그래프, Parent-Child Hierarchy) 도입. 중복 Chunk 문제 해결.
- 검색용 임베딩 Fine-tuning: Chunk 분리용 임베딩과 차별화.
(표 2) Chunk Features 예시 1 (AI 도입과 주 4일제 관련)
Chunk Title Candidate Questions Query Rewrite
| 유럽 AI 노동 현장 도입 | 유럽에서는 AI가 어떻게 노동 현장에 도입되고 있나요? | 유럽 AI 노동 현장 도입 |
| 2023년 영국 테크.코 데이터 | 2023년 영국의 테크.코에서 수집한 데이터는 무엇인가요? | AI 도입되는 이유 |
| 주 4일 근무제 조직 AI 활용 | 주 4일 근무제를 시행하는 조직은 몇 %이며, 이들은 회사 운영에 AI를 어떻게 활용하고 있나요? | 주 4일제 조직 AI 활용 |
(표 3) Chunk Features 예시 2 (아파트 화재 배상 책임 관련)
Chunk Title Candidate Questions Query Rewrite
| 아파트 화재 시 손해배상책임 | '실화책임에 관한 법률'에도 불구하고 아파트의 소유자가 보험금액의 범위에서 손해를 배상해야 하는 이유는 무엇인가요? | 아파트 화재 시 손해 배상 이유 |
| 화재 재해보상 보험가입 법률 | "화재로 인한 재해보상과 보험가입에 관한 법률"은 어떤 경우에 적용되나요? | 화재 재해보상 보험가입 법률 |
| 특수건물 | 특수건물에는 어떤 것들이 있나요? | 특수건물 |
5. 결론:
공공데이터 기반 RAG 시스템 구축. 효율적인 Chunking 및 Retrieval 전략으로 정확하고 풍부한 정보 제공.
문서 검토는 이제 Document AI로 한방에! / 황세윤 (카카오페이손해보험)
- 핸드폰 파손 보장 보험 서류 검토와 관련된 기술
- Document AI란?: 기계 학습과 자연어 처리 기술을 이용하여 문서 내용을 자동으로 인식하고 처리하는 기술.
- 목표: SaaS형 서비스 및 파트너십을 통해 Document AI 기술 주권 확립.
- 영수증 인식 과정: 4단계로 구성

- Edge Detection (경계 감지): 이미지에서 경계선을 감지하는 단계
- Layout Analysis (레이아웃 분석): 텍스트, 이미지 등 구성 요소의 위치와 관계를 파악하는 단계
- OCR (광학 문자 인식): 이미지에서 텍스트를 추출하는 단계
- Parsing (파싱, 정보 이해): 추출된 텍스트에서 필요한 정보를 추출하고 구조화하는 단계. 본 자료에서는 JSON 형태로 구조화함.
- 결론: AI 기반 시스템 월 170만원 정도로 사람보다 정확하고 빠르면서도 저렴함
기타
카카오헬스케어 exhibition 파스타 관련
- 건강 컨텐츠 관련 챗봇 업데이트 예정
- 300개의 컨텐츠 RAG 시스템
- 당뇨 타겟에서 일반인으로 타겟 확대 예정
- kanana와 협업 내년에 논의 예정