

1. LLM evlauation
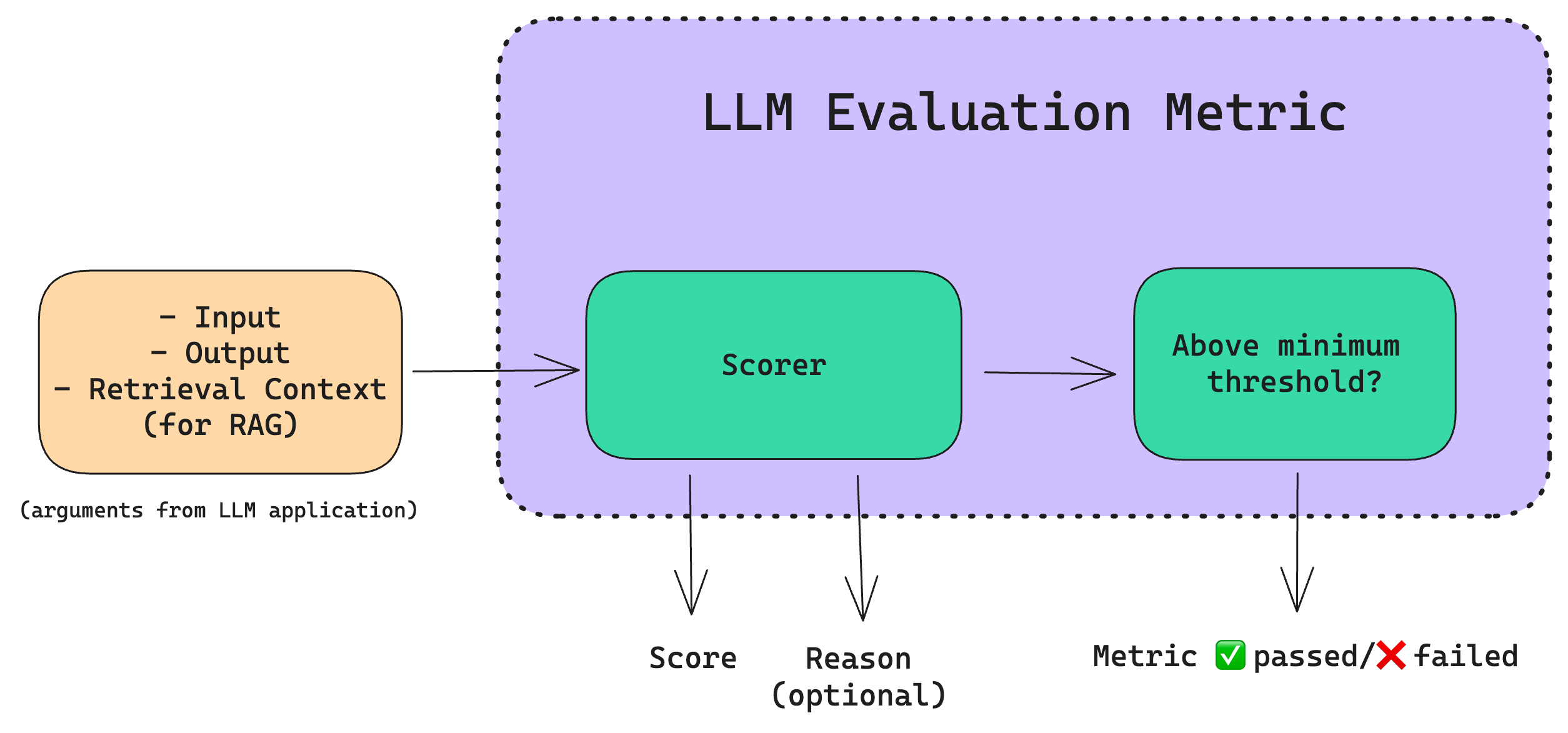
- LLM 평가는 어려운 문제 중 하나임
- 대중적으로 많이 사용되고 있는 무료 프레임워크 두개 소개
- 보통 4가지 구성요소 있으면 됨
1) question
2) answer
3) context(RAG)
4) ground_truth

2. DeepEval.

- Metrics and Features

- Git
https://github.com/confident-ai/deepeval
GitHub - confident-ai/deepeval: The LLM Evaluation Framework
The LLM Evaluation Framework. Contribute to confident-ai/deepeval development by creating an account on GitHub.
github.com
3. ragas

- Quickstart
from datasets import Dataset
import os
from ragas import evaluate
from ragas.metrics import faithfulness, answer_correctness
os.environ["OPENAI_API_KEY"] = "your-openai-key"
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[faithfulness,answer_correctness])
score.to_pandas()- Git
https://github.com/explodinggradients/ragas
GitHub - explodinggradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines
Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines - explodinggradients/ragas
github.com